


Побудова лінійної регресійної моделі
ЗМІСТ
1. Основні параметри проведення економетричного аналізу
2. Метод найменших квадратів
3. Оцінка параметрів лінійної регресії за методом найменших квадратів
4. Властивості простої лінійної регресії
5. Коефіцієнти кореляції та детермінації
6. Ступені вільності, аналіз дисперсій.
7. Перевірка простої регресійної моделі на адекватність.
8. F - критерій Фішера
Задача
Література
1. Основні параметри проведення економетричного аналізу
Багато явищ у природі і суспільстві взаємозалежні. Якщо узимку багато снігу - навесні чекай повеней. Якщо погана екологія - це до хвороб. Якщо перед курортний сезон - росте попит (і ціни) на купальники. Практично будь-яке явище зв'язане з багатьма факторами (причинами), що приведе до складності і неоднозначності аналізу.
Серед різних типів зв'язку нас буде цікавити так називаний статистичний (стохастичний) зв'язок між масовими явищами. Коли досліджується вплив якогось фактора на цікавлячий нас результат, то говорять про причинно-наслідковий зв'язок між фактором Х і результатом Y. Статистика успадковує з цього зв'язку лише термінологію (фактор і результат), суть же статистичного зв'язку принципово відрізняється від причинно-наслідкового.
Розрізняють функціональний (детерминированний) і статистичний зв'язок. Під функціональним зв'язком розуміють залежність у = у(х) при якому кожному значенню аргументу х (фактора) ставиться у відповідність відоме (детерминироване) значення функції (мал. 1, а). Наприклад, закон Ньютона а = F/m (прискорення тіла а прямо пропорціонально силі F і обратнопропорціонально масі m) являє приклад прямої функціональної залежності між а (функцією) і F (аргументом). Зв'язок називають статистичним, якщо для кожного фіксованого значення х€X існує безліч можливих значень показника Y (мал. 1, б). Звичайно Y розглядається як випадкова величина, що має для кожного фіксованого значення х0 розподіл умовних імовірностей P{Y= yk|х0} чи щільність імовірності р(у|х0). Якщо при зміні фактора х істотно змінюється і розподіл показника Y, то говорять про наявність істотного статистичного зв'язку між Х і Y. Про такий зв'язок можна в першому наближенні судити вже по зміні середнього значення показника Y - умовного математичного чекання: ![]()
який тут записано для безупинної випадкової величини Y. Умовне математичне чекання M(Y | х) має сенс середнього значення показника Y при деякім відомому значенні фактора х. Цю залежність як функцію аргументу х у теорії ймовірностей називають лінією регресії. Вона зображена як приклад на мал. 1,6.
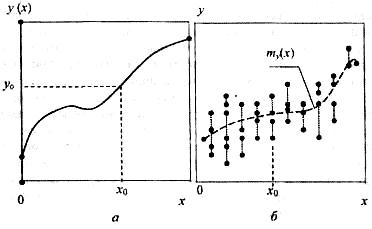
Рис. 1.
У літературі по эконометрике немає однозначної термінології у відношенні X і Y. Зокрема, зустрічаються такі пари термінів, як регрессор (X) і регрессант (Y), що пояснює X (незалежна, екзогенна) і що пояснюється Y (залежна, ендогенна) перемінні й ін. Ми будемо дотримувати найбільш розповсюджених і лаконічних термінів: Х- фактор, Y- показник.
Відмінність статистичного зв'язку від причинно-наслідкової полягає в наступному. У теорії імовірностей (і математичній статистиці) для випадкових величин X і Y доведено, що якщо Y залежить від X, те і X залежить від Y. Скажемо, пропозиція Y залежить від попиту X, споживання морозива - від сезона. Це причинно-наслідкові залежності. Навряд чи можна погодиться, що сезон залежить від споживання морозива. Це буде правдою лише наполовину (з погляду причинно-наслідкового зв'язку). Тим часом сезон (статистично) залежить від рівня споживання морозива. Інакше кажучи, за результатом ми можемо судити про причину на основі статистичного досвіду. Якщо хладо-комбинат працює на граничних потужностях, напевно в розпалі літо. Якщо случився неврожай, то була посуха. Якщо літак розбився, комісія досліджує найбільш ймовірні причини катастрофи (на основі наблюдання і статистики) і зробить висновок.
У эконометриці (як і у статистикі) приходиться мати справу з вибірками обмеженого обсягу п і замість імовірностей (плотностей імовірності) оперувати їх оцінками -частостями (чи відносними частотами). При цьому на основі вибірки можна побудувати апроксимацію (наближену функцію) лінії регресії. Такі лінії регресії описують функціональну складову математичних моделей статистичної залежності між фактором X і показником Y. Вони використовуються для оцінок і прогнозів в економічних і фінансових розрахунках, при плануванні бізнесу і розподілі інвестиційних потоків.
Часткою случаємо статистичного зв'язку є кореляційний зв'язок. Вона оцінюється коефіцієнтом кореляції, що характеризує ступінь лінійного статистичного зв'язку.
При вивченні взаємозв'язків між економічними явищами зважуються наступні задачі:
- вибір типу моделі регресії;
- побудова моделі обраного типу (визначення параметрів моделі);
- прогнозування середнього значення показника для заданого значення фактора;
- оцінка помилок моделювання і прогнозу;
- оцінка впливу факторних ознак на значення показника (імітаційне моделювання);
- дисперсійно-кореляційний аналіз моделі і встановлення істотності (значимості) статистичного зв'язку між фактором і показником;
- оцінка адекватності результатів моделювання явищам, що спостерігаються.
Дані є вихідним матеріалом при побудові моделей. Показники в послідовно узяті моменти часу називають тимчасовими рядами (рядами динаміки). Це можуть бути показники інфляції, курсів валют, цін і т.д. через визначені інтервали часу. Такі дані часто є коррелированными тим більше, чим менше тимчасові інтервали. Температура на вулиці через годину менше зміниться (більше коррелирована з попередньої), чим через день чи місяць.
Дані, що не є тимчасовими, прийнято називати просторовими. Звичайно вони збираються з рознесених просторово точок і є крапками вибірки обсягу п і розмірності до к= т + 1 (число к на 1 більше числа факторів т). Вимоги репрезентативності вибірки припускають випадковість добору і достатній обсяг вибірки з виконанням умови п >> к. Це завжди варто пам'ятати при побудові моделей, І інакше можливе одержання зміщених оцінок. Про середній курс долара в місті, наприклад, не можна судити по обмінних пунктах у районі міського вокзалу. Прикладами просторових даних є дані по виробництву, продажу, споживанню, цінам у різних точках міста (країни) у визначений момент часу. На макроекономічному рівні це можуть бути дані по розподілі трудових і матеріальних ресурсів по регіонах країни.
2. Метод найменших квадратів
Модель парної лінійної регресії є власне кажучи лінійною апроксимацією (наближенням) реальної лінії регресії у(х) як умовного математичного чекання випадкового показника Y. Специфікація моделі може бути записана як: ![]()
![]()
Тут передбачається, що α і β - точні значення параметрів моделі; хі - відомі вибіркові значення фактора; εі - випадкові помилки моделі в і-й точці з імовірностними властивостями генеральної сукупності. Очевидно, випадкові значення показника yі при цих умовах мають той же розподіл, що і помилки εі (зі зсувом ![]() ). Для спрощення запису ми позначаємо параметри моделі β0=α, β1=β.
). Для спрощення запису ми позначаємо параметри моделі β0=α, β1=β.
Оскільки на практиці замість генеральної сукупності приходиться мати справу з вибіркою обмеженого обсягу п, вдається одержати засноване на вибіркових даних наближення: yi=a+bxi+ei; i=1,2,…,
де параметри а і b моделі є лише деякими оцінками точних значень параметрів α і β. Теоретична залежність (ТЗ) двомірної МЛР (чи апроксимуюча функція f(X, β)) описується рівнянням прямої лінії: у = а+ bх.
Тут множник b називається коефіцієнтом регресії, а величина а - постійної складової лінії регресії.
Коефіцієнт регресії ![]() характеризує збільшення показника при збільшенні фактора на 1 (dx = 1) і має відповідну розмірність. При зміні постійна складової а пряма коллинеарно переміщається, а її розмірність збігається з розмірністю у. Пряма лінія у = а+ bх повинна проходити так, щоб стосовно точок вибірки обсягу п
характеризує збільшення показника при збільшенні фактора на 1 (dx = 1) і має відповідну розмірність. При зміні постійна складової а пряма коллинеарно переміщається, а її розмірність збігається з розмірністю у. Пряма лінія у = а+ bх повинна проходити так, щоб стосовно точок вибірки обсягу п ![]()
забезпечити мінімальну середньоквадратичну помилку (СКП). Метод визначення параметрів моделі з мінімальної СКП називається методом найменших квадратів (МНК чи LSM- Least Squares Method в англомовній літературі).
Безліч точок вибірки ![]() на графіку рис. 1 у декартовых координатах х,у називають діаграмою розсіювання.
на графіку рис. 1 у декартовых координатах х,у називають діаграмою розсіювання.
Для кожної крапки вибірки помилка результату вибірки (залишок регресії) дорівнює еі = уі - уі* = уі – а - і
Ця помилка для і-й точки представлена на рис. 2.