


Універсальні мікропроцесори, застосовувані в ММПС. Мікропроцесори з архітектурою Itanium (IA-64)
ВСТУП
1. УНІВЕРСАЛЬНІ МІКРОПРОЦЕСОРИ, ЗАСТОСОВУВАНІВ ММПС
1.1 Типи архітектур універсальних мікропроцесорів
1.2.Архітектура PENTIUM
1.2.1 Призначення функціональних блоків
1.3 Архітектура PENTIUM MMX
1.4 Архітектура PENTIUM PRO (P6)
2. МІКРОПРОЦЕСОРи з АРХіТЕКТУРОЮ ITANIUM (IA-64)
2.1 Формати та засіб обробки команд
2.2 Структурна схема ITANIUM
2.3 Призначення програмних регістрів
ЛІТЕРАТУРА
ВСТУП
Тема реферату «Універсальні мікропроцесори, застосовувані в ММПС. Мікропроцесори з архітектурою Itanium (IA-64)» з дисципліни «Мультимікропроцесорні системи».
Мультимікропроцесорні системи (ММПС) - це системи, що мають два й більше компонент, які можуть одночасно виконувати команди. Підпорядкованими процесорами можуть бути спецпроцесори, розраховані на виконання певного типу завдання або процесори широкого застосування. Спецпроцесори - співпроцесори, процесори вводу-виводу.
У міру зменшення відносини вартість/продуктивність стає більше економічним застосовувати кілька мікропроцесорів (далі ─ МП), замість одного складного
Крім поліпшення економічних показників системи, мультипроцесорні конфігурації забезпечують кілька позитивних якостей, відсутніх в однопроцесорній конфігурації.
Кілька процесорів краще пристосовуються під вимогу конкретного застосування, крім витрат на непотрібні можливості централізованої системи. Більше того, модульність ММПС дозволяє в міру необхідності вводити додаткові процесори.
У ММПС завдання розподіляються між модулями. При виникненні відмови у системі простіше та дешевше знайти й замінити несправний процесор, чим заміняти (відшукувати) елемент, що відмовив, у складному процесорі.
1. УНІВЕРСАЛЬНІ МІКРОПРОЦЕСОРИ, ЗАСТОСОВУВАНІ В ММПС
1.1 Типи архітектур універсальних мікропроцесорів
Домінуюче положення на ринку мікропроцесорів займають мікропроцесори фірми Intel - 90 % усього виробництва, інші 10 % - RISC процесори. Існують наступні типи архітектур МП:
- архітектура х86 - фірма Intel (Pentium P5,P6, P-PRO, P-MMX), фірма AMD (K5,K6), фірма CYRIX (M1,M2);
- архітектура PA - фірма HP (PA-8000);
- архітектура ALPHA - фірма DEC (ALPHA 21064, 21164,21164A);
- архітектура SPARS - фірма SUN (лінія SPARS);
- архітектура MIPS - компанія SILICON GRAPHICS (лінія MIPS R-X (R1000));
Ті самі МП використаються в ПЕОМ, робочих станціях і супер-ЕОМ. У двох останніх випадках найчастіше використаються симетричні МП і обчислювальні системи з масовим паралелізмом.
На сьогоднішній день всі основні виробники мікропроцесорів мають приблизно рівні технологічні можливості, тому в боротьбі за основну характеристику (тактова частота) виходить фактор архітектури.
На даний момент часу існують два напрямки розвитку архітектури:
- SPEED DAEMON - досягнення високої продуктивності за рахунок підвищення тактової частоти;
- BRAINIAC - досягнення високої продуктивності за рахунок ускладнення логіки планування обчислень і внутрішньої структури МП. Загальна особливість всіх МП - високошвидкісна обробка 64-розрядних операндів з фіксованою й плаваючою крапкою.
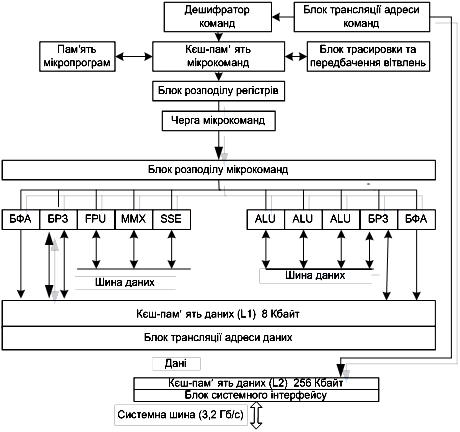
Малюнок 1. Структура мікропроцесора Pentium 4
Технічні характеристики:
- тактова частота від 60 до 200 Мгц;
- близька до суперскалярної архітектура;
- роздільні К-П даних і команд;
- пророкування переходів;
- високопродуктивні операції із плаваючою крапкою;
- удосконалена 64-розрядна шина даних;
- наявність засобів забезпечення цілісності даних;
- SL-технології із засобами керування;
- підтримка багатопроцесорності;
- підтримка різних розмірів сторінок пам'яті;
- моніторинг продуктивності.
Суперскалярна організація (виконання декількох команд за один такт) здійснюється за рахунок двох конвеєрів.
Подвійний конвеєр Pentium виконує целочислені команди в п'ять етапів:
- передвиборка;
- декодування 1;
- декодування 2;
- виконання;
- запис результатів.
При цьому кілька команд можуть перебувати на різних етапах виконання (конвеєри залежні, тобто при зупинці одного, зупиняється й другий ).
мікропроцесор pentium itanium
1.2.1 Призначення функціональних блоків
К-П частково асоціативна з розміром рядка рівним 32 байтам. Буфер TLB перетворить адресу комірки зовнішньої пам'яті у відповідну адресу даних у К-П. К-П даних використає метод зворотного запису й протокол MESI. Наявність блока предсказування переходів - перший тип МП із такою характеристикою. Виконання твердження переходів здійснюється через буфер BTB і два буфери попередньої вибірки. Перший буфер - для попередньої вибірки команд у припущенні, що переходу немає. Другий буфер – під час передвиборки використується буфер BTB, у якому зберігається вміст при виконанні переходу. Підтримуються й вкладені цикли, тому що BTB зберігає кілька адрес переходів і до 256 результатів переходів.
Операції із плаваючою крапкою
Блок операцій із плаваючою крапкою розташований усередині кристала й використовує складні 8-рівневі конвеєри й внутрішні функції. Більшість команд із плаваючою крапкою починають виконуватися в одному із цілочисельних конвеєрів, а потім передаються на конвеєри із плаваючою крапкою. Функції додавання, ділення й множення реалізовані як внутрішні функції. Блок із плаваючою крапкою Pentium у порівнянні з i486 виконує операції в 10 разів швидше.
64-розрядна шина даних
При цій шині даних обмін МП із пам'яттю здійснюється зі швидкістю 528 Мбайт /с, тобто в 5 разів перевищує максимальну швидкість IntelDX2 66 Мгц - 105 Мбайт/с.
Розширена шина даних підтримує потік команд і даних, переданих суперскалярному виконавчому процесорному ядру, що сприяє підвищенню інтенсивності обробки. У результаті загальна продуктивність в 2,5 рази вище IntelDX2.
Крім цього, Pentium організує конвеєризацію циклів шини, що дозволяє почати другий цикл до завершення першого. Це дає підсистемі пам'яті більше часу для декодування адреси й внаслідок чого можна застосовувати більше повільні й менш дорогі елементи пам'яті, що відбивається на вартості системи. Крім того, збільшенню пропускної здатності й надійності системи сприяє підтримка пакетного читання й запису, перевірка парності адреси й даних.
Для підвищення швидкості виконання послідовних операцій запису в пам'ять Pentium має два буфери запису ( по одному на кожний конвеєр), завдяки яким процесор може продовжувати роботу, виконуючи наступні команди, хоча результат однієї з поточних команд ще не записаний в пам'ять через зайнятість шини.
Засоби забезпечення цілісності даних
Забезпечення внутрішнього виявлення помилок (наявність бітів парності внутрішніх буферів процесора), а також тестування за допомогою функціональної надмірності (використання двох МП - основного й що перевіряє). У парі ці МП виконують паралельні обчислення. Один МП порівнює результати обчислень із результатами обчислень другого МП. У випадку непорівняння результатів генерується переривання.
Керування енергоспоживанням
Здійснюється на двох рівнях - на рівні МП і на рівні системи. На першому рівні - при виконанні завдань, не потребуючі виконання інтенсивних обчислень (редагування текстів), переклад МП у режим зі зниженою тактовою частотою й зниженою напругою живлення. Можливий навіть SL- режим (сплячий). На другому рівні використається режим SMM (System Management Mode), що контролює енергоспоживання у всім ПК (включаючи периферійні пристрої). Цей режим забезпечує інтелектуальне керування системою, що дозволяє МП сповільнювати функціонування, припиняти або повністю припиняти роботу окремих системних компонентів.
Підтримка мультипроцесорності
Здійснюється з використанням протоколу когерентності К-П MESI, а також за допомогою контролера багатопроцесорних переривань, що підтримує до 60 процесорів і 2-входового контролера К-П другого рівня, що дозволяє двом процесорам спільно використати одну К-П другого рівня.
Підтримка різних розмірів сторінок пам'яті
Для першого режиму розмір сторінок дорівнює 4 Кб, а для другого - 4 Мб. Для програмного забезпечення цей режим прозорий. Він уведений для зменшення частоти перемикання сторінок у складних графічних додатках і ядрі операційної системи.
Моніторинг продуктивності
Це засіб, що дозволяє проектувальникам системи й розроблювачам додатків оптимізувати апаратне й програмне забезпечення, завдяки виявленню в програмному коді «вузьких місць». Розроблювачі можуть спостерігати й підраховувати такти для внутрішніх процесорних подій, що впливають на продуктивність операції читання й записи, на промах і влучення в К-П, перериванню, використання системної шини.
1.3 Архітектура PENTIUM MMX
МП Pentium ММХ містить у собі всі функції Pentium плюс 57 додаткових команд (реалізація мультимедійних алгоритмів), цифрова обробка сигналів, операції над векторами, згортка, перетворення Фур'є.
Також реалізовані подвоєні обсяги К-П даних і команд ( по 16 Кбайт кожна), розширена конвеєризація - 6 команд. Поліпшено логіку пророкування переходів і здійснена більше глибока буферізація пам'яті.
Для виконання додаткового набору команд використається ММХ - пристрій і блок регістрів із плаваючою крапкою. Додані 8 ММХ регістрів (ММ0-ММ7). Вони фізично сполучені з 64-розрядними регістрами із плаваючою крапкою тому що можуть бути використані тільки над операціями із ММХ даними.
Швидкість виконання мультимедійних операцій на 60 % вище в порівнянні з Pentium.
1.4 Архітектура PENTIUM PRO (P6)
Застосовується при проектуванні старших моделей робочих станцій і мультипроцесорних систем. Ефект використання досягається тільки для 32-розрядних додатків. Нова конструкція корпуса, що складається із двох мікросхем, поміщених в один керамічний корпус і не погодиться з виводами Pentium. У випадку використання Pentium-PRO необхідний перехід на нові системні плати.
Тактова частота - 133 Мгц (для технології 0,6мкм), і 200 Мгц (для технології 0,35мкм). Потужність розсіювання - 14 Вт.
Висока продуктивність у Р-РRO забезпечується за рахунок використання нововведень в архітектурі й технології, а саме - рознесена архітектура, динамічне виконання команд, подвійна незалежна шина.
Нова архітектура К-П – DIB -передбачає використання різних шин для з'єднання процесорного ядра з К-П і основною оперативною пам'яттю. Перша шина працює на тактовій частоті процесора, друга із частотою системи. Такий поділ шин дозволило в три рази прискорити обмін процесора з підсистемою пам'яті.Завдяки цьому відпадає необхідність у зовнішньої К-П.
МП містить роздільні К-П першого рівня для даних і команд, кожна обсягом 8 Кбайт, і об'єднану К-П другого рівня. К-П даних першого рівня двухпортова, що не блокує , підтримує одну операцію завантаження й одну операцію запису за такт.
Інтерфейс К-П другого рівня працює з тактовою частотою центрального процесора й може передавати 64 біта за такт. Зовнішня шина МП працює з 1/2, 1/3, 1/4, тактової частоти центрального процесора.
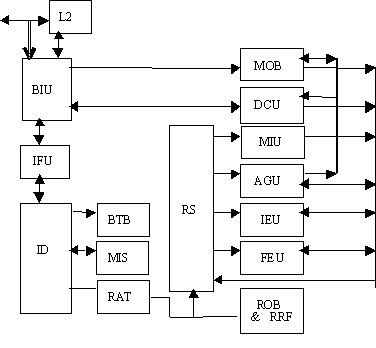
Малюнок 2. Структура PENTIUM PRO
BUI - пристрій інтерфейсу із шиною;
IFU - пристрій підкачування команд ( з К-П команд);
BTB - буфер адрес переходів;
ID - декодер команд;
MIS - планувальник мікрокоманд;
RAT - таблиця псевдонімів регістрів;
ROB - буфер переупорядкування;
RRF - файл регістрів вивантаження;
RS - станція, що резервує;
IEU - пристрій цілочисельних команд;
FEU - пристрій команд із плаваючою крапкою;
AGU - пристрій генерації адреси;
MUI - пристрій інтерфейсу з пам'яттю;
DCU - пристрій керування К-П даних;
МОВ - буфер переупорядкування звертань до пам'яті
L2 - К-П другі рівні.
512-елементний буфер адрес переходів (ВТВ -Branch Target Buffer) дозволяє скоротити число тактів при вибірці рядків з К-П пристроєм підкачування команд. Процес вибірки конвеєризований. Новий рядок вибирається кожний такт центрального процесора. Три паралельних декодери кожний такт перетворюють кілька команд архітектури х86 у набори мікрооперацій.
Таблиця псевдонімів регістрів використається для перейменування регістрів. Результат перейменування посилає в пристрій резервування й у буфер переупорядкування.
Мікрооперації з перейменованими операндами містяться в чергу в пристрої резервування, де очікують значень операндів, що надходять незалежно від декількох джерел. Даними є результати виконаної мікрооперації, адреси із ВТВ, уміст регістрів.
Вибір мікрооперацій із черги й динамічне виконання здійснюється з обліком їхніх істинних залежностей по даним, а також залежно від доступності виконавчих пристроїв (IEU, FEU,AGU). Порядок, у якому виконуються мікрооперації, у загальному випадку відрізняється від їхнього розташування у вихідній програмі.
При плануванні звертань до пам'яті використається пристрій резервування, пристрій генерації адреси, і буфер переупорядкування звертань до пам'яті.
Мікрооперація стає кандидатом на вивантаження відразу, як тільки вона виконана, визначена адреса переходу й отриманих результатів спрямовані до нужденній у них мікрооперації. Для відновлення первісного порядку мікрооперацій використаються тимчасові мітки мікрооперацій у буфері переупорядкування й файлі регістрів вивантаження. Процес вивантаження повинен забезпечити не тільки відновлення первісного порядку мікрооперацій, але й гарантувати правильну обробку переривань і помилок, а також скасовувати всі або частина результатів, отриманого після неправильного пророкування розгалуження. У момент вивантаження мікрооперації її результат з буфера переупорядкування міститься у файл регістрів вивантаження.
2. МІКРОПРОЦЕСОРи з АРХіТЕКТУРОЙ ITANIUM (IA-64)
Початок випуску –2001 рік, технологія 0,18мкм з тактовою частотою 660,733,800 Мгц, концепція EPIC (Explicity Parallel Instruction Computing) –явне паралельне виконання команд. Основні особливості концепції:
1.Велика кількість регістрів;
2.Масштабування по кількості функціональних пристроїв (можливість збільшення числа функціональних пристроїв в подальших моделях мікропроцесора);
3.Явне завдання паралелізму в машинному коді;
4.Предикативне виконання інструкцій;
5.Попереджуюче завантаження даних по припущенню;
Відмінність між функціями архітектури i86 і ITANIUM приведені в табл.1
Таблиця 1
| Архітектура i86 | Архітектура ITANIUM |
| Використовування складних інструкцій змінної довжини, оброблюваних по одній | Використовування простих інструкцій однакової довжини, згрупованих по три в групі |
| Переупорядковування і оптимізація інструкцій під час виконання | Переупорядковування і оптимізація інструкцій під час компіляції |
| Спроби прогнозу переходів | Виконання декількох послідовностей команд одночасно без прогнозу переходів |
| Завантаження даних з пам'яті у міру потреби | Завантаження даних з пам'яті до того, як вони будуть потрібно |