


Нормы и интерпретация результатов теста
Глава XIV
ПРОСТЕЙШИЕ МЕТОДЫ
СТАТИСТИЧЕСКОЙ ОБРАБОТКИ МАТЕРИАЛОВ ПСИХОЛОГИЧЕСКИХ ИССЛЕДОВАНИЙ
Статистические методы применяются при обработке материалов психологических исследований для того, чтобы извлечь из тех количественных данных, которые получены в экспериментах, при опросе и наблюдениях, возможно больше полезной информации. В частности, в обработке данных, получаемых при испытаниях по психологической диагностике, это будет информация об индивидуально-психологических особенностях испытуемых. Вообще психологические исследования обычно строятся с опорой на количественные данные. Вот пример.
К школьному психологу обратился шестиклассник Саня Ю. с просьбой испытать его двигательный темп. Саню очень интересовал баскетбол, и он собирался вступить в баскетбольную команду, а баскетболист, несомненно, должен иметь высокий двигательный темп. Психолог разработал план небольшого исследования. Он начал с того, что попросил Саню так быстро, как он только может, ставить точки в центре кружков, нарисованных на листке бумаги. За одну минуту Саня поставил 137 точек. Насколько этот темп характерен для Сани? Чтобы установить это, психолог попросил Саню повторить эту пробу 25 раз. Действительно, некоторые результаты превышали первоначально полученное число, но некоторые оказались и поменьше. Психолог просуммировал все полученные за 25 проб результаты, а сумму разделил на 25 — таким путем он получил среднее арифметическое по всем пробам. Это среднее арифметическое составило 141. Таков по этой пробе максимальный темп Сани. Можно ли считать этот темп высоким? Потребовался еще один шаг в исследовании. Психолог сформировал группу из 50 шестиклассников, не отличающихся ни от Сани, ни друг от друга по возрасту более чем на полгода. С этими ребятами психолог также провел сначала по несколько тренировочных проб, чтобы получить надежные данные об их темпе, и, наконец, последнюю пробу, для обработки.
Все эти экспериментальные данные в виде средних арифметических были построены в один порядковый ряд, который был разбит по десяткам (по децилям). Санины данные вышли в десятку с наиболее быстрыми результатами. По этим количественным данным психолог сделал вывод о том, что Саня обладает сравнительно высоким двигательным темпом, о чем и было ему сообщено.
Современная математическая статистика представляет собой большую и сложную систему знаний. Нельзя рассчитывать на то, что каждый психолог, сделавший диагностику своей специальностью, овладеет этими знаниями. Между тем статистика нужна психологу постоянно в его повседневной работе. Специалисты-статистики разработали целый комплекс простых методов, которые совершенно доступны любому человеку, не забывшему то, что он выучил еще в средней школе.
В зависимости от требований, которые предъявляют к статистике различные области науки и практики, создаются пособия по геологической, медицинской, биологической, психологической статистике. (См., например: Суходольский Г.В. Основы математической статистики для психологов. Л., 1972). В этой главе даются простейшие методы статистики для психологов. Все необходимые для их применения вычисления можно выполнять на ручном компьютере, а то и на простых счетах. Уместное, грамотное применение этих методов позволит практику и исследователю, проведя начальную обработку, получить общую картину того, что дают количественные результаты его исследований, оперативно проконтролировать ход исследований. В дальнейшем, если возникнет такая необходимость, материалы исследований могут быть переданы для более глубокой разработки специалисту-статистику на большой компьютер.
Статистические шкалы. Применение тех или других статистических методов определяется тем, к какой статистической шкале относится полученный материал. С. Стивене предложил различать четыре статистические шкалы: шкалу наименований (или номинативную), шкалу порядка, шкалу интервалов и шкалу отношений.
Зная типические особенности каждой шкалы, нетрудно установить, к какой из шкал следует отнести подлежащий статистической обработке материал.

 Шкала наименований. К этой шкале относятся материалы, в которых изучаемые объекты отличаются друг от друга по их качеству. При обработке таких материалов нет никакой нужды в том, чтобы располагать эти объекты в каком-то порядке, исходя из их характеристик. В принципе объекты можно располагать в любой последовательности. Вот пример: изучается состав международной научной конференции. Среди участников есть французы, англичане, датчане, немцы и русские (рис. 1). Имеет ли значение порядок, в котором будут расположены участники при изучении состава конференции? Можно расположить их по алфавиту, это удобно, но ясно, что никакого принципиального значения в этом расположении нет. При переводе этих материалов на другой язык (а значит, и на другой алфавит) этот порядок будет нарушен. Можно расположить национальные группы по числу участников. Но при сравнении этого материала с материалом другой конференции найдем, что вряд ли этот порядок окажется таким же. Отнесенные к шкале наименований объекты можно размещать в любой последовательности в зависимости от цели исследования.
Шкала наименований. К этой шкале относятся материалы, в которых изучаемые объекты отличаются друг от друга по их качеству. При обработке таких материалов нет никакой нужды в том, чтобы располагать эти объекты в каком-то порядке, исходя из их характеристик. В принципе объекты можно располагать в любой последовательности. Вот пример: изучается состав международной научной конференции. Среди участников есть французы, англичане, датчане, немцы и русские (рис. 1). Имеет ли значение порядок, в котором будут расположены участники при изучении состава конференции? Можно расположить их по алфавиту, это удобно, но ясно, что никакого принципиального значения в этом расположении нет. При переводе этих материалов на другой язык (а значит, и на другой алфавит) этот порядок будет нарушен. Можно расположить национальные группы по числу участников. Но при сравнении этого материала с материалом другой конференции найдем, что вряд ли этот порядок окажется таким же. Отнесенные к шкале наименований объекты можно размещать в любой последовательности в зависимости от цели исследования.
При статистической обработке такого рода материалов нужно считаться с тем, каким числом единиц представлен каждый объект. Имеются весьма эффективные статистические методы, позволяющие по этим числовым данным прийти к научно значимым выводам (например, метод хи-квадрат).
Шкала порядка. Если в шкале наименований порядок следования изучаемых объектов практически не играет никакой роли, то в шкале порядка — это видно из ее названия — именно на эту последовательность переключается все внимание. К этой шкале в статистике относят такие исследовательские материалы, в которых рассмотрению подлежат объекты, принадлежащие к одному или нескольким классам, но отличающиеся при сравнении одного с другим: больше—меньше, выше—ниже и т.п.
Проще всего показать типические особенности шкалы порядка, если обратиться к публикуемым итогам любых спортивных соревнований. В этих итогах последовательно перечисляются участники, занявшие соответственно первое, второе, третье и прочие по порядку места. Но в информации об итогах соревнований нередко отсутствуют или отходят на второй план сведения о фактических достижениях спортсменов, а на первый план ставятся их порядковые места. Допустим, шахматист Д. занял в соревнованиях первое место. Каковы же его достижения? Оказывается, он набрал 12 очков. Шахматист Е. занял второе место. Его достижение — 10 очков.
Третье место занял Ж. с 8 очками, четвертое — З. с 6 очками и т.д. В сообщениях о соревновании разница в достижениях при размещении шахматистов отходит на второй план, а на первом остаются их порядковые места. В том, что именно порядковому месту отводится главное значение, есть свой смысл. В самом деле, в нашем примере 3. набрал 6, а Д. — 12 очков. Это абсолютные их достижения — выигранные ими партии. Если попытаться истолковать эту разницу в достижениях чисто арифметически, то пришлось бы признать, что 3. играет вдвое хуже, чем Д. Но с этим нельзя согласиться. Обстоятельства соревнований не всегда просты, как не всегда просто и то, как провел их тот или другой участник. Поэтому, воздерживаясь от арифметической абсолютизации, ограничиваются тем, что устанавливают: шахматист 3. отстает от занявшего первое место Д. на три порядковых места.
Заметим, что в других соревнованиях расклад абсолютных достижений может быть иным: занявший первое место может всего на пол-очка опережать ближайших участников. Важно, что он набрал наибольшее количество очков. Только от этого зависит его порядковое место.
Шкала интервалов. К ней относятся такие материалы, в которых дана количественная оценка изучаемого объекта в фиксированных единицах. Вернемся к опытам, которые провел психолог с Саней. В опытах учитывалось, сколько точек может поставить, работая с максимально доступной ему скоростью, сам Саня и каждый из его сверстников. Оценочными единицами в опытах служило число точек. Подсчитав их, исследователь получил то абсолютное число точек, которое оказалось возможным поставить за отведенное время каждому участнику опытов. Главная трудность при отнесении материалов к шкале интервалов состоит в том, что нужно располагать такой единицей, которая была бы при всех повторных измерениях тождественной самой себе, т.е. одинаковой и неизменной. В примере с шахматистами (шкала порядка) такой единицы вообще не существует.
В самом деле, учитывается число партий, выигранных каждым участником соревнований. Но ясно, что партии далеко не одинаковы. Возможно, что участник соревнований, занявший четвертое место — он выиграл шесть партий, — выиграл труднейшую партию у самого лидера! Но в окончательных итогах как бы принимается, что все выигранные партии одинаковы. В действительности же этого нет. Поэтому при работе с подобными материалами уместно их оценивать в соответствии с требованиями шкалы порядка, а не шкалы интервалов. Материалы, соответствующие шкале интервалов, должны иметь единицу измерения.
Шкала отношений. К этой шкале относятся материалы, в которых учитываются не только число фиксированных единиц, как в шкале интервалов, но и отношения полученных суммарных итогов между собой. Чтобы работать с такими отношениями, нужно иметь некую абсолютную точку, от которой и ведется отсчет. При изучении психологических объектов эта шкала практически неприменима.
О параметрических и непараметрических методах статистики. Приступая к статистической обработке своих исследований, психолог должен решить, какие методы ему более подходят по особенностям его материала — параметрические или непараметрические. Различие между ними легко понять. Вспомним, что говорилось об измерении двигательной скорости шестиклассников. Как обработать эти данные? Нужно записать все произведенные измерения — в данном случае это будет число точек, поставленных каждым испытуемым, — затем требуется вычислить для каждого испытуемого среднее арифметическое по результатам опытов. Далее следует расположить все эти данные в их последовательности, например, начиная с наименьших к наибольшим. Для облегчения обозримости этих данных их обычно объединяют в группы; в этом случае можно объединить по 5—9 измерений в группе. Вообще же при таком объединении желательно, если общее число случаев не более ста, чтобы общее число групп было порядка двенадцати. Получилась такая таблица (с. 249).
Далее нужно установить, сколько раз в опытах встретились числовые значения, соответствующие каждой группе. Сделав это, нужно для каждой группы записать ее численность. Полученные в такой таблице данные носят название распределения численностей. Рекомендуется представить это распределение в виде диаграммы — полигона распределения. Контуры этого полигона помогут решить вопрос о статистических методах обработки. Нередко они напоминают контуры колокола, с наивысшей точкой в центре полигона и с симметричными ветвями, отходящими в ту и другую сторону. Такой контур соответствует кривой нормального распределения. Это понятие было введено в математическую статистику К.Ф. Гауссом (1777—1855), поэтому кривую именуют также кривой Гаусса. Он же дал математическое описание этой кривой. Для построения кривой Гаусса (или кривой нормального распределения) теоретически требуется очень большое количество случаев. Практически же приходится довольствоваться тем фактическим материалом, который накоплен в исследовании. Если данные, которыми располагает исследователь, при их внимательном рассмотрении или после переноса их на диаграмму, лишь в незначительной степени расходятся с кривой нормального распределения, то это дает право исследователю применять в статистической обработке параметрические методы, исходные положения которых основываются на нормальной (О математически обоснованных способах определения того, можно ли считать данное распределение нормальным, см., например, в кн.: Урбах В.Ю. Математическая статистика для биологов и медиков. М., 1963. С. 66) кривой распределения Гаусса. Нормальное распределение называют параметрическим потому, что для построения и анализа кривой Гаусса достаточно иметь всего два параметра: среднее арифметическое, значение которого должно соответствовать высоте перпендикуляра, восстановленного в центре кривой, и так называемое среднее квад-ратическое, или стандартное, отклонение — величины, характеризующей размах колебаний данной кривой; о способах вычисления той и другой величины будет далее рассказано.
Параметрические методы обладают для исследователя многими преимуществами, но нельзя забывать о том, что применение их правомерно только тогда, когда обрабатываемые данные показывают распределение, лишь несущественно отличающееся от гауссова.
При невозможности применить параметрические методы, надлежит обратиться к непараметрическим. Эти методы успешно разрабатывались в последние 3—4 десятилетия, и их разработка была вызвана прежде всего потребностями ряда наук; в частности, психологии. Они показали свою высокую эффективность. Вместе с тем они не требуют сложной вычислительной работы.
Современному психологу-исследователю нужно исходить из того, что «существует большое количество данных либо вообще не поддающихся анализу с помощью кривой нормального распределения, либо не удовлетворяющих основным предпосылкам, необходимым для ее использования» (Рунион Р. Справочник по непараметрической статистике. М., 1982. С. 11.).
Генеральная совокупность и выборка. Психологу постоянно придется иметь дело с этими двумя понятиями. Генеральная совокупность, или просто совокупность, — это множество, все элементы которого обладают какими-то общими признаками. Так, все подростки-шестиклассники 12 лет (от 11,5 до 12,5) образуют совокупность. Дети того же возраста, но не обучающиеся в школе, или же обучающиеся, но не в шестых классах, не подлежат включению в эту совокупность.
В ходе конкретизации проблем своего исследования психологу неизбежно придется обозначить границы изучаемой им совокупности. Следует ли включать в изучаемую совокупность детей того же возраста, но обучающихся в колледжах, гимназиях, лицеях и других подобных учебных заведениях? В ответе на этот и на другие такие же вопросы может помочь статистика.
В подавляющем большинстве случаев исследователь не в состоянии охватить в изучении всю совокупность. Приходится, хотя это и связано с некоторой утратой информации, взять для изучения лишь часть совокупности, ее и называют выборкой. Задача исследователя заключается в том, чтобы подобрать такую выборку, которая репрезентировала бы, представляла совокупность; другими словами, признаки элементов совокупности должны быть представлены в выборке. Составить такую выборку, в точности повторяющую все разнообразные сочетания признаков, которые имеются в элементах совокупности, вряд ли возможно. Поэтому некоторые потери в информации оказываются неизбежными. Важно, чтобы в выборке были сохранены существенные, с точки зрения данного исследования, признаки совокупности. Возможны случаи, и для их обнаружения есть статистические методы, когда задачи исследования требуют создания двух выборок одной совокупности; при этом нужно установить, не взяты ли выборки из разных совокупностей. Эти и другие подобные казусы нужно иметь в виду психологу при обработке результатов выборочных исследований.
Следует рассмотреть типы задач, с которыми чаще всего имеет дело психолог. Соответственно приводятся и статистические методы, которые приложимы для обработки психологических материалов, направленных на решение этих задач.
Первый тип задач. Психологу нужно дать сжатую и достаточно информативную характеристику психологических особенностей какой-то выборки, например, школьников определенного класса. Чтобы подойти к решению этой задачи, необходимо располагать результатами диагностических испытаний; эти испытания, разумеется, следует заранее спланировать так, чтобы они давали информацию о тех особенностях группы, которые в этом конкретном случае интересуют психолога. Это могут быть особенности умственного развития, психофизиологические особенности, данные об изменении работоспособности и т.д.
Получив все экспериментальные результаты и материалы наблюдений, следует подумать о том, как их подать пользователю в компактном виде, чтобы при этом свести к минимуму потерю информации. В перечне статистических методов, используемых при решении подобных задач, обычно находят свое место и параметрические и непараметрические методы, о возможностях применения тех и других, как было сказано выше, судят по полученному материалу. Об этих статистических методах и их использовании пойдет речь ниже.
Второй тип задач. Это, пожалуй, наиболее часто встречающиеся задачи в исследовательской и практической деятельности психолога: сравниваются между собой несколько выборок, чтобы установить, являются ли выборки независимыми или принадлежат одной и той же совокупности. Так, проведя эксперименты в восьмых классах двух различных школ, психолог сравнивает эти выборки между собой.
К этому же типу относятся задачи с определением тесноты связи двух рядов показателей, полученных на одной и той же выборке; в такой обработке чаще всего применяют метод корреляций.
Третий тип задач — это задачи, в которых обработке подлежат временные ряды, в них расположены показатели, меняющиеся во времени; их называют также динамическими рядами. В предшествующих типах задач фактор времени не принимался во внимание и материал анализировался так, как будто он весь поступил в руки исследователя в одно и то же время. Такое допущение можно оправдать тем, что за тот короткий период времени, который был затрачен на собирание материала, он не потерпел существенных изменений. Но психологу приходится работать и с таким материалом, в котором наибольший интерес представляют как раз его изменения во времени. Допустим, психолог намерен изучить изменение работоспособности школьников в течение учебной четверти. В этом случае информативными будут показатели, по которым можно судить о динамике работоспособности. Берясь за такой материал, психолог должен понимать, что при анализе динамических рядов нет смысла пользоваться средним арифметическим ряда, так как оно замаскирует нужную информацию о динамике.
В предыдущих главах упоминалось о лонгитюдинальном исследовании, т.е. таком, в котором однообразный по содержанию психологический материал по одной выборке собирается в течение длительного времени. Показатели лонгитюда — это также динамические ряды, и при их обработке следует пользоваться методами, предназначенными для таких рядов.
Четвертый тип задач — задачи, возникающие перед психологом, занимающимся конструированием диагностических методик, проверкой и обработкой результатов их применения. Отчасти об этих задачах уже говорилось в других главах, но не уделялось внимания специально статистике. Психологическая диагностика, в особенности тестология, имеет целый ряд канонических правил, применение которых должно обеспечивать высокое качество информации, получаемой посредством диагностических методик. Так, методика должна быть надежной, гомогенной, валидной. По упрочившимся в тестологии правилам, все эти свойства проверяются статистическими методами.
Здесь уместно высказать некоторые соображения о возможностях статистики в проведении психологического исследования.
Статистика как таковая не создает новой научной информации. Эта информация либо содержится, либо не содержится (к сожалению, и так бывает) в полученных исследователем материалах. Назначение статистики состоит в том, чтобы извлечь из этих материалов больше полезной информации. Вместе с тем статистика показывает, что эта информация не случайна и что добытые данные имеют определенную и значимую вероятность.
Статистические методы раскрывают связи между изучаемыми явлениями. Однако необходимо твердо знать, что как бы ни была высока вероятность таких связей, они не дают права исследователю признать их причинно-следственными отношениями. Статистика, как о ней пишут известные английские ученые Д.Э. Юл и М.Дж. Кендэл (Теория статистики. М., 1960. С. 18—19.), «вынуждена принимать к анализу данные, подверженные влиянию множества причин». Статистика, например, утверждает, что существует значимая связь между двигательной скоростью и игрой в теннис. Но отсюда еще не вытекает, будто двигательная скорость и есть причина успешной игры. Нельзя, по крайней мере в некоторых случаях, исключить и того, что сама двигательная скорость явилась следствием успешной игры.
Чтобы подтвердить или отвергнуть существование причинно-следственных отношений, исследователю зачастую приходится продумывать целые серии экспериментов. Если они будут правильно построены и проведены, то статистика поможет извлечь из результатов этих экспериментов информацию, которая необходима исследователю, чтобы либо обосновать и подтвердить свою гипотезу, либо признать ее недоказанной.
Вот что нужно знать при использовании статистики.
Итак, были перечислены типы задач, с которыми чаще всего встречаются психологи. Теперь перейдем к изложению конкретных статистических методов, которые способствуют успешному решению перечисленных задач.
Первый тип задач. Статистические методы, примеры их применения для принятия решения.
Допустим, школьному психологу нужно представить краткую информацию о развитии психомоторных функций учащихся 6-х классов, в которых обучается 50 учеников. В процессе выполнения своей программы психолог провел диагностическое изучение двигательной скорости, применив методику, которая была описана выше (С. 240).
Для реализации своей программы психологу надлежало получить количественные характеристики, свидетельствующие о состоянии изучаемой функции — ее центральной тенденции, величины, показывающей размах- колебаний, в пределах которого находятся все данные отдельных учеников, и то, как распределяются эти данные.
Какими методами вести обработку — параметрическими или непараметрическими? Визуальное ознакомление с полученными данными показывает, что возможно применение параметрического метода, т.е. будут вычислены среднее арифметическое, выражающее центральную тенденцию, и среднее квадратическое отклонение, показывающее размах и особенности варьирования экспериментальных результатов.
Нельзя ограничиться вычислением только среднего арифметического, так как оно не дает полных сведений об изучаемой выборке. Вот пример. В одном купе вагона поместилась бабушка 60 лет с четырьмя внуками: 4 лет, двое по 5 и 6 лет. Среднее арифметическое возраста всех пассажиров этого купе 80/5 = 16.
В другом, купе расположилась компания молодежи: двое 15-летних, 16-летний и двое 17-летних. Средний возраст пассажиров этого купе также равен 16. Таким образом, по средним арифметическим пассажиры этих купе как бы и не различаются. Но если обратиться к особенностям варьирования, то сразу можно установить, что в одном купе возраст пассажиров варьирует в пределах 56 единиц, а во втором — в пределах 2.
Для вычисления среднего арифметического применяется формула:
![]()
а для среднего квадратического отклонения формула:
![]()
![]() В этих формулах х означает среднее арифметическое, х — каждую величину изучаемого ряда, Z — сумму; s — среднее квадратическое отклонение; п — число членов изучаемого ряда.
В этих формулах х означает среднее арифметическое, х — каждую величину изучаемого ряда, Z — сумму; s — среднее квадратическое отклонение; п — число членов изучаемого ряда.
Вернемся к опыту с проверкой двигательной скорости учащихся (С. 244).
В опытах участвовали 50 испытуемых. Каждый из них выполнил по 25 проб, по 1 минуте каждая. Вычислена средняя каждого испытуемого. Полученный ряд упорядочен и все индивидуальные результаты представлены в последовательности от меньшего к большему:
85 — 93 — 93 — 99 — 101 — 105 — 109 — 110 — 111 — 115 —
115 — 116 — 116 — 117 — 117 — 117 — 118 — 119 — 121 — 121 —
122 — 124 — 124 — 124 — 124 — 125 — 125 — 125 — 127 — 127 —
127 — 127 — 127 — 128 — 130 — 131 — 132 — 132 — 133 — 134 —
134 — 135 — 138 — 138 — 140 — 143 — 144 — 146 — 150 — 158
Для дальнейшей обработки удобнее эти первичные данные соединить в группы, тогда отчетливее выступает присущее данному ряду распределение величин и их численностей. Отчасти упрощается и вычисление среднего арифметического и среднего квадратического отклонения. Этим искупается несущественное искажение/ информации, неизбежное при вычислениях на сгруппированные данных.
При выборе группового интервала следует принять во внимание такие соображения. Если ряд не очень велик, например содержит до 100 элементов, то и число групп не должно быть очень велико, например порядка 10—12. Желательно, чтобы при группировании начальная величина — при соблюдении последовательности от меньшей величины к большей — была меньше самой меньшей величины ряда, а самая большая — больше самой большой величины изучаемого ряда. Если ряд, как в данном случае, начинается с 85, группирование нужно начать с меньшей величины, а поскольку ряд завершается числом 158, то и группирование должно завершаться большей величиной. В ряду, который нами изучается, с учетом высказанных соображений можно выбрать групповой интервал в 9 единиц и произвести разбиение ряда на группы, начав с 83. Тогда последняя группа будет завершаться величиной, превышающей значение последней величины ряда (т.е. 158). Число групп будет равно 9 (табл. 1).
Вычисление среднего арифметического и среднего квадратическо-го отклонения.
Таблица 1
| Группы | Средние значения | Результат разноски | Итоги разноски | f•x |
|
|
|
| 83—91 | 87 |
| 1 | 87 | 36 | 1296 | 1296 |
| 92—100 | 96 | u | 3 | 288 | 27 | 729 | 2187 |
| 101—109 | 105 | LJ | 3 | 315 | 18 | 324 | 972 |
| 110—118 | 114 | 10 | 1140 | 9 | 81 | 810 | |
| 119—127 | 123 | 1300/ | 16 | 1968 | 0 | 0 | 0 |
| 128—136 | 132 | Ш | 9 | 1188 | 9 | 81 | 729 |
| 137—145 | 141 | Я | 5 | 705 | 18 | 324 | 1620 |
| 146—154 | 150 | L | 2 | 300 | 27 | 729 | 1458 |
| 155—163 | 159 | / | 1 | 159 | 36 | 1296 | 1296 |
= 50 | Σf•x= 6150 |
|
 /
/1-й столбец — группы, полученные после разбиения изучаемого ряда.
2-й столбец — средние значения каждой группы; этот столбец показывает, в каком диапазоне варьируют величины изучаемого ряда, т.е. х.
3-й столбец показывает результаты «ручной» разноски величин ряда или иксов: каждая величина занесена в соответствующую ее значению группу в виде черточки.
4-й столбец — это итог подсчета результатов разноски.
5-й столбец показывает, сколько раз встречалась каждая величина ряда — это произведение величин второго столбца на величины 4-го столбца по строчкам. Итоги 4-го и 5-го столбцов дают суммы, необходимые для вычисления среднего арифметического.
![]() 6-й столбец показывает разность среднего арифметического и значения x по каждой группе.
6-й столбец показывает разность среднего арифметического и значения x по каждой группе.
7-й столбец — квадрат этих разностей.
8-й столбец показывает, сколько раз встречался каждый квадрат разности; суммирование величин этого столбца дает итог, необходимый для вычисления среднего квадратического отклонения.
В заголовках 5-го и 8-го столбцов указывается, насколько часто встречается та или другая величина. Частота обозначается буквой f (от английского слова frequency).
Включение буквы f, означающей, насколько часто встречалась та или другая величина, ничего не изменяет в формулах среднего арифметического и среднего квадратического отклонения.
Поэтому формулы
![]()
![]()
вполне тождественны.
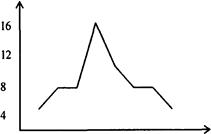
Рис.2
Остается показать, как вычисляются по формулам среднее арифметическое и среднее квадратическое отклонение. Обратимся к величинам, полученным в таблице:
![]() x = 6150 : 50 = 123. При составлении таблицы это число было заранее вычислено, без него нельзя было бы получить числовые значения 6, 7, 8-го столбцов таблицы.
x = 6150 : 50 = 123. При составлении таблицы это число было заранее вычислено, без него нельзя было бы получить числовые значения 6, 7, 8-го столбцов таблицы.
![]()
При обработке изучаемого ряда оказалось возможным применение параметрического метода, так как визуально в этом ряду распределение численностей приближается к нормальному. Это подтверждается и графиком (рис. 2, с. 251).
![]()
![]()
![]()
![]() Нормальное распределение обладает некоторыми весьма полезными для исследователя свойствами. Так, в границах x ± s находится примерно 68% всего ряда или всей выборки, в границах х ± 2s — примерно 95%, а в границах x ± 3s — 97,7% выборки. В практике исследований часто берут границы — x ±2/3s. В этих границах при нормальном распределении будут находиться 50% выборки; распределение это симметрично, поэтому 25% окажутся ниже, а 25% выше границ x ±2/3s. Все эти расчеты не требуют никакой дополнительной проверки при условии, что изучаемый ряд имеет нормальное распределение, а число элементов в нем велико, порядка нескольких сотен или тысяч. Для рядов, которые распределены нормально или имеют распределение, мало отличающееся от нормального, вычисляется коэффициент вариации по такой формуле:
Нормальное распределение обладает некоторыми весьма полезными для исследователя свойствами. Так, в границах x ± s находится примерно 68% всего ряда или всей выборки, в границах х ± 2s — примерно 95%, а в границах x ± 3s — 97,7% выборки. В практике исследований часто берут границы — x ±2/3s. В этих границах при нормальном распределении будут находиться 50% выборки; распределение это симметрично, поэтому 25% окажутся ниже, а 25% выше границ x ±2/3s. Все эти расчеты не требуют никакой дополнительной проверки при условии, что изучаемый ряд имеет нормальное распределение, а число элементов в нем велико, порядка нескольких сотен или тысяч. Для рядов, которые распределены нормально или имеют распределение, мало отличающееся от нормального, вычисляется коэффициент вариации по такой формуле:
![]()
В примере, который был рассмотрен выше,
V= (100-14,4)/123 = 11,7.
Выполнив все эти вычисления, психолог может представить информацию об изучении двигательной скорости с помощью примененной методики в 6-х классах. Согласно результатам изучения в 6-х классах получены: среднее арифметическое — 123; среднее квадратическое отклонение — 14,4; коэффициент вариативности — 11,7.
Непараметрические методы. Ранжирование, медиана, квартиль. Далеко не все материалы, получаемые в психологических исследованиях, подлежат обработке параметрическими методами. Если после ознакомления с изучаемым рядом исследователь убеждается в том, что этот ряд не имеет свойств нормального распределения, ему остается перейти на методы непараметрической статистики. С их помощью могут быть получены и центральная тенденция изучаемого ряда — медиана — и величина, позволяющая судить о диапазоне варьирования и о строении изучаемого ряда — квартильное отклонение.
Вот пример. После диагностических испытаний уровня умственного развития учеников 6-го класса полученные данные были упорядочены, т.е. расположены в последовательности от меньшей величины к большей. Испытания проходили 18 учащихся (табл. 2).
Таблица 2
| Учащиеся | Баллы | Ранги (R) | Учащиеся | Баллы | Ранги (R) |
| А | 25 | 1 | К | 68 | 10 |
| Б | 28 | 2 | Л | 69 | 11,5 |
| В | 39 | 4 | М | 69 | 11,5 |
| Г | 39 | 4 | Н | 70 | 14,5 |
| Д | 39 | 4 | О | 70 | 14,5 |
| Е | 45 | 6 | П | 70 | 14,5 |
| Ж | 50 | 7 | Р | 70 | 14,5 |
| 3 | 52 | 8,5 | С | 74 | 17,5 |
| И | 52 | 8,5 | Т | 74 | 17,5 |
Примечание. Буквами обозначены учащиеся, числами — полученные ими баллы по тесту.
Процедура ранжирования состоит в следующем. Все числа ряда в их последовательности получают по своим. порядковым местам присваиваемые им ранги. Если какие-нибудь числа повторяются, то всем повторяющимся числам присваивается один и тот же ранг — средний из общей суммы занятых ими ранговых мест. Так, числу 28 в изучаемом ряду присвоен ранг 2. Затем следуют трижды повторяющиеся числа 39. На них приходятся занятые ими ранговые места 3, 4, 5. Поэтому этим числам присваивается один и тот же средний ранг, в данном случае — 4. Поскольку места до 5-го включительно заняты, то следующее число получает ранг 6 и т.д.
При обработке ряда, не имеющего признаков нормального распределения — непараметрического ряда, — для величины, которая выражала бы его центральную тенденцию, более всего пригодна медиана, т.е. величина, расположенная в середине ряда. Ее определяют по срединному рангу по формуле Me = (п + 1)/2, где Me — означает медиану, п — как в ранее приводившихся формулах — число членов ряда. При нечетном числе членов ряда ранговая медиана — целое число, при нечетном число — с 0,5. Заметим, что числовое значение медианы может и не быть в составе самого обрабатываемого ряда.
Возьмем к примеру ряд в семь членов: 3—5—6—7—9—10—11.
Проранжировав его, имеем: 1—2—3—4—5—6—7.
Ранговая медиана в таком ряду равна: Me = (7 + 1)/2 = 4, этот ранг приходится на величину 7.
Возьмем ряд в восемь членов: 3—5—6—7—9—10—11—12.
Проранжировав его, имеем: 1—2—3—4—5—6—7—8.
Ранговая медиана в этом ряду равна: Me = (8 + 1)/2 = 4,5.
Этому рангу соответствует середина между двумя величинами, имеющими ранг 4 и ранг 5, т.е. между 7 и 9. Медиана этого ряда равна: Me = (7 + 9)/2 = 8.
Следует обратить внимание на то, что величины 8 в составе ряда нет, но таково значение медианы этого ряда.
Вернемся к изучаемому ряду. Он состоит из 18 членов. Его ранговая медиана равна: Me = (18 + 1)/2 = 9,5.
Она расположится между 9-й и 10-й величиной ряда. 9-я величина — 52, 10-я — 68. Медиана занимает срединное место между ними, следовательно, Me = (52 + 68)/2 = 60.
По обе стороны от этой величины находится по 50% величин ряда.
Характеристику распределения численностей в непараметрическом ряду можно получить из отношения его квартилей. Квартилью называется величина, отграничивающая 1/4 всех величин ряда. Квартиль первая — ее обозначение Q1 — вычисляется по формуле:
![]()
Это полусумма первого и последнего рангов первой — левой от медианы половины ряда;
квартиль третья, обозначаемая Q3 вычисляется по формуле:
![]()
т.е. как полусумма первого и последнего рангов второй, правой от медианы, половины ряда. Берутся порядковые значения рангов по их последовательности в ряду. В обрабатываемом ряду Q1 = (1+9)/2 = 5, Q3 = (10 + 18)/2 = 14.
Рангу 5 в этом ряду соответствует величина 39, а рангу 14 — 70. Следовательно, в данном ряду Q1 = 39, а Q3= 70.