


Имитационное моделирование работы парикмахерской
Имитационное моделирование основано на прямом описании моделируемого объекта. Существенной характеристикой таких моделей является структурное подобие объекта и модели. Это значит, каждому существенному с точки зрения решаемой задачи элементу объекта ставится в соответствие элемент модели. При построении имитационной модели описываются законы функционирования каждого элемента объекта и связи между ними. Работа с имитационной моделью заключается в проведении имитационного эксперимента. Процесс, протекающий в модели в ходе эксперимента, подобен процессу в реальном объекте. Поэтому исследование объекта на его имитационной модели сводится к изучению характеристик процесса, протекающего в ходе эксперимента.
В теории систем массового обслуживания (в дальнейшем просто – CMО) обслуживаемый объект называют требованием. В общем случае под требованием обычно понимают запрос на удовлетворение некоторой потребности, например, обслуживание автомобиля на заправочной станции, разговор с абонентом, посадка самолета, покупка билета, получение материалов на складе и т д.
На первичное развитие теории массового обслуживания оказали особое влияние работы датского ученого А.К. Эрланга (1878-1929).
Теория массового обслуживания – область прикладной математики, занимающаяся анализом процессов в системах производства, обслуживания, управления, в которых однородные события повторяются многократно, например, на предприятиях бытового обслуживания; в системах приема, переработки и передачи информации; автоматических линиях производства. В теории СМО рассматриваются такие случаи, когда поступление требований происходит через случайные промежутки времени, а продолжительность обслуживания требований не является постоянной, т.е. носит случайный характер. В силу этих причин одним из основных методов математического описания СМО является аппарат теории случайных процессов. Основной задачей теории СМО является изучение режима функционирования обслуживающей системы и исследование явлений, возникающих в процессе обслуживания. Так, одной из характеристик обслуживающей системы является время пребывания требования в очереди. Очевидно, что это время можно сократить за счет увеличения количества обслуживающих устройств. Однако каждое дополнительное устройство требует определенных материальных затрат, при этом увеличивается время бездействия обслуживающего устройства из-за отсутствия требований на обслуживание, что также является негативным явлением. Следовательно, в теории СМО возникают задачи оптимизации: каким образом достичь определенного уровня обслуживания (максимального сокращения очереди или потерь требований) при минимальных затратах, связанных с простоем обслуживающих устройств.
Цель курсовой работы по дисциплине «Имитационное моделирование экономических процессов» - ознакомление с современными концепциями построения моделирующих систем, с основными приемами имитационного моделирования, встраиваемыми в общуюпроцедуру преобразования информации от структурирования и формализации составляющих предметных областей до интерпретации обработанных данных и приобретенных знаний, связанных с описанием экономических процессов. Данная работа представляет собой работу по созданию и реализации математической модели системы массового обслуживания для получения необходимых нам результатов на основании исходных данных и известных математических зависимостей.
Целью данной курсовой работы является моделирование работы парикмахерской, создав программу на языке С++, анализ работы парикмахерской; имитирующую работу парикмахеров за определенное время; время и цену обслуживания одного клиента, выручку парикмахерской, средний размер очереди, число отказов и т д.
Глава 1 Теоретический анализ методов решения задачи
1.1 Анализ предметной области
Одной из динамично развивающихся сфер является сфера оказания парикмахерских услуг. Парикмахерская — это предприятие, занимающееся предоставлением услуг для населения по уходу за волосами (стрижка, завивка, создание причёски, окраска, мелирование и другие виды работ с красителями, бритьё и стрижка бород и усов и др.) в оборудованном специально для этого помещении. Как правило, в парикмахерских дополнительно оказываются следующие виды услуг: маникюр, педикюр, косметические услуги и услуги визажиста. В настоящее время в парикмахерской можно получить услуги солярия и косметолога.
Парикмахерские, согласно действующему стандарту, в зависимости от ассортимента и качества оказываемых услуг бывают следующих видов:
· парикмахерская;
· парикмахерская-салон;
· парикмахерская-люкс.
Специалисты, работающие в парикмахерской, называются парикмахерами. Парикмахер, парикмахер-стилист — специалист в области создания стиля человека с помощью причёски. Среди парикмахеров существуют следующие специализации:
· Специалист по мужским стрижкам (мужской мастер).
· Специалист по окрашиванию волос (парикмахер-колорист).
· Специалист по женским прическам (женский мастер).
· Специалиста по мужским и женским стрижкам
Виды услуг, предлагаемые парикмахерами:
· Лечение волос
· Стрижка волос
· Окраска волос (колорирование)
· Укладка волос
1.2 Теоретический обзор методов решения задачи
1.2.1 Метод Монте-Карло
В конце 40-х годов американские физики применили для вычисления на ЭВМ сложных квадратур метод, основанный на вероятностных законах. Этот метод был назван ими методом Монте-Карло, имея в виду Монте-Карло как мировой центр игр, исход которых определяется случаем. Суть метода станет ясной из следующего примера. Предположим, что требуется определить площадь s под некоторой кривой ![]() на отрезке
на отрезке ![]() , то есть вычислить значение определённого интеграла
, то есть вычислить значение определённого интеграла ![]() (1). Это можно сделать следующим образом. Будем выбирать случайные точки в прямоугольнике
(1). Это можно сделать следующим образом. Будем выбирать случайные точки в прямоугольнике![]() площадью
площадью ![]() (см. рис.1) и считать число точек
(см. рис.1) и считать число точек ![]() , попавших под кривую
, попавших под кривую ![]() . Тогда при общем числе
. Тогда при общем числе ![]() выбранных точек, отношение
выбранных точек, отношение ![]() , очевидно, будет приближённо равным отношению искомой площади
, очевидно, будет приближённо равным отношению искомой площади ![]() под кривой
под кривой ![]() на отрезке
на отрезке ![]() к площади
к площади![]() прямоугольника. Откуда искомая площадь может быть вычислена по формуле
прямоугольника. Откуда искомая площадь может быть вычислена по формуле![]() причём вычисленное таким образом значение будет тем ближе к точному значению интеграла (1), чем больше точек
причём вычисленное таким образом значение будет тем ближе к точному значению интеграла (1), чем больше точек ![]() взято и чем более равномерно распределены точки внутри прямоугольника.
взято и чем более равномерно распределены точки внутри прямоугольника.
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
Рис.1.Искомая площадь S
Проблема состоит в том, чтобы получить на ЭВМ случайные числа с равномерным распределением. Действительно, ЭВМ представляет собой детерминированное устройство, которое при одних и тех же условиях всегда выдает один и тот же результат.
Одним из очевидно напрашивающихся представляется решение получить случайную последовательность каким-либо из известных физических методов, например с помощью рулетки, какие используются в казино, после чего записать эти случайные числа во внешнюю память ЭВМ с целью последующего использования в программе. Однако это потребовало бы значительных затрат времени для получения достаточно длинной случайной последовательности, с одной стороны, и внешней памяти для её сохранения, с другой. Следует отметить также тот факт, что в момент появления метода ресурсы внешней памяти ЭВМ были весьма ограничены. Другим возможным решением было бы применить непосредственно какой-либо физический метод генерации случайных чисел с помощью специально сконструированного для этих целей подключаемого к ЭВМ аппаратного устройства и далее получать с его помощью случайные числа непосредственно во время работы программы.
В качестве основы для такого устройства можно было бы использовать какой-либо электронный прибор, например электронную лампу, вырабатывающие случайные уровни потенциала, обусловленные тепловыми флуктуациями. Такие устройства могут быть сконструированы, однако возникают проблемы с устойчивостью их работы во времени и при изменении условий окружающей среды; существует также проблема сертификации подобного устройства. В итоге исследователи остановились на более простой и оказавшейся в дальнейшем продуктивной идее генерации вместо случайной так называемой псевдослучайной, последовательности чисел с помощью специально разработанного для этих целей алгоритма.
1.2.2 Метод Неймана
Для получения псевдослучайной последовательности Фон Нейманом был придуман простой в вычислительном отношении алгоритм, известный как метод квадратов. Метод состоит в многократном повторении процедуры, состоящей в возведении в квадрат некоторого числового значения и взятия средних цифр полученного результата. Пусть, например, мы выбрали в качестве исходного значения число ![]() . Тогда
. Тогда ![]() и
и ![]() ,
, ![]() и
и ![]() , и так далее. Однако вскоре у метода обнаружился недостаток, заключающийся в существенной неравномерности статистических частот различных числовых значений элементов получаемой этим методом последовательности.
, и так далее. Однако вскоре у метода обнаружился недостаток, заключающийся в существенной неравномерности статистических частот различных числовых значений элементов получаемой этим методом последовательности.
1.2.3 Мультипликативный конгруэнтный метод
Этот метод основан на рекуррентном вычислении элементов псевдослучайной последовательности как результата выполнения операции сравнения по некоторому заданному основанию. Переход к следующему числу последовательности производится простым умножением результата сравнения на некоторую заданную константу. На практике операции вычисления произведения и взятия сравнения по заданному основанию совмещены. В качестве основания сравнения используется величина ![]() , где m– разрядность целочисленного регистра ЭВМ, в котором хранится результат вычисления произведения.
, где m– разрядность целочисленного регистра ЭВМ, в котором хранится результат вычисления произведения.
При целочисленном умножении этого результата на заданную константу достаточно большой величины происходит переполнение, вследствие чего в регистре результата сохраняются лишь mмладших разрядов произведения. Это число фактически и будет результатом операции сравнения вычисленного произведения с числом ![]() , (напомним, что операцией сравнения по некоторому основанию называется вычисление остатка от деления первого операнда на это основание).
, (напомним, что операцией сравнения по некоторому основанию называется вычисление остатка от деления первого операнда на это основание).
Формально схема вычисления может быть определена следующим образом: ![]() = С,
= С, ![]() (mod
(mod![]() ), где
), где ![]() i-ый член псевдослучайной последовательности, С – некоторая константа, m – разрядность целочисленного регистра ЭВМ. Качество полученной псевдослучайной последовательности зависит от выбранного значения константы С. Установлено, что хороший результат достигается при выборе ее значения равным максимальной нечетной степени числа 5, помещающегося в числовом регистре фиксированной разрядности. Для 32-х разрядного регистра ЭВМ это число будет
i-ый член псевдослучайной последовательности, С – некоторая константа, m – разрядность целочисленного регистра ЭВМ. Качество полученной псевдослучайной последовательности зависит от выбранного значения константы С. Установлено, что хороший результат достигается при выборе ее значения равным максимальной нечетной степени числа 5, помещающегося в числовом регистре фиксированной разрядности. Для 32-х разрядного регистра ЭВМ это число будет ![]() .
.
1.2.4 Равномерное распределение
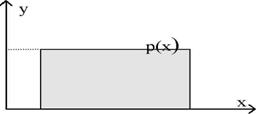
Случайная величина ξ, с равномерным распределением на отрезке (а,) описывается функцией плотности вероятности:
P(x)=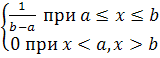
![]()
a b
Рис.2 Равномерное распределение
Математическое ожидание
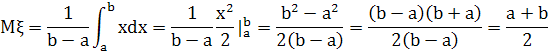
Для вычисления дисперсии вначале вычислим математическое ожидание квадрата этой случайной величины:
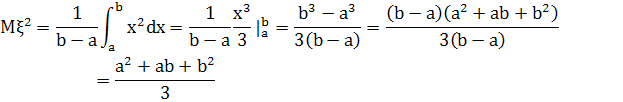
Теперь:
![]() =
=![]()
1.2.5 Моделирование дискретной случайной величины
Предположим вначале, что нам требуется смоделировать простейшую дискретную случайную величину, принимающую два значения с равными вероятностями. Эта случайная величина моделирует выбрасывание жребия или монеты. Если мы имеем в своем распоряжении генератор псевдослучайных последовательностей, описанный в предыдущем параграфе, то задача может быть решена следующим, достаточно очевидным, способом. Поскольку псевдослучайное число, получаемое с помощью функции rand(), распределено равномерно в интервале (0,1), то одинаково вероятно, будет ли очередное полученное значение принадлежать левой половине этого интервала (0,0.5) или правой (0.5, 1). По этой причине мы можем одно из двух значений нашей случайная величина поставить в соответствие первому из этих двух подинтервалов, а в другое – второму, и далее выдавать значения в зависимости от того к какому из этих двух подинтервалов будет принадлежать очередное выпавшее значение генератора rand(). Эта схема, очевидно, легко обобщается на дискретную случайная величина, принимающую более двух значений. За каждым значением мы должны в этом случае «закрепить» некоторый подинтервал значений функции rand() с длиной, равной вероятности этого значения моделируемой дискретной случайная величина, - причем так, чтобы интервалы , закрепленные за различными значениями случайные величины не пересекались бы между собой. Поскольку сумма вероятностей всех значений случайная величина равна 1, и таков же диапазон значений, принимаемых псевдослучайной величиной, генерируемой функцией rand(), то эти подинтервалы полностью покроют диапазон возможных значений, принимаемых случайная величина, генерируемой функцией rand().
Теперь мы должны лишь всякий раз определять, к какому из множеству выбранных указанным выше образом подинтервалов принадлежит очередное выданное функцией rand() значение, и выдавать соответствующее ему значение моделируемой дискретной случайная величина.
Формально этот метод может быть представлен в следующем виде. Пусть ![]() – случайная величина, равномерно распределенная на отрезке (0,1) (в нашем случае – это результат очередного выполнения функции rand()) и
– случайная величина, равномерно распределенная на отрезке (0,1) (в нашем случае – это результат очередного выполнения функции rand()) и ![]() – моделируемая дискретная случайная величина с распределением
– моделируемая дискретная случайная величина с распределением ![]() . Тогда мы выдаем по получении очередного значения g случайной величины
. Тогда мы выдаем по получении очередного значения g случайной величины ![]() такое значение
такое значение ![]() дискретной случайной величины
дискретной случайной величины ![]() , для которого верно двойное неравенство
, для которого верно двойное неравенство ![]() . Этим исчерпывается решение задачи моделирования дискретной случайной величины с заданным распределением. Вышеприведенный алгоритм легко реализуется программно, - например так, как в нижеприведенной функции int discrete (float p()):
. Этим исчерпывается решение задачи моделирования дискретной случайной величины с заданным распределением. Вышеприведенный алгоритм легко реализуется программно, - например так, как в нижеприведенной функции int discrete (float p()):
unsigned int discrete (float p())
{
float s, r;
int k=0;
s=p(0); r=rand();
while (s < r)
{
k++;
s=s+p(k);
}
return k;
}
Функция принимает массив вероятностей моделируемой дискретной случайной величины и выдает индекс очередного ее сгенерированного значения. Следует учесть, что поскольку индексация массивов в языке С начинается с нуля, также с нуля индексируются значения разыгрываемой случайной величины. То есть функция выдает значения в диапазоне от 0 до к-1 для дискретной случайной величины, принимающей к значений. Ниже для иллюстрации приведен ряд из 100 значений выданных программой, использующей вызов данной функции для массива вероятностей p={0.5, 0.5}:
0 1 1 1 0 0 0 1 1 1 1 1 1 0 1 0 0 1 1 0 1 1 0 0 0 0 0 1 0 1 0 0 0
1 0 1 0 0 1 0 1 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0
1 0 1 0 1 1 1 0 0 1 1 0 1 0 1 0 0 1 1 1 1 0 0 0 0 1 0 1 0 0 0 0 1
1.2.6 Моделирование случайной величины, равномерно распределенной в интервале (a,)
![]() Мы используем метод обратной функции для моделирования равномерного и показательного распределений. Решаем уравнение
Мы используем метод обратной функции для моделирования равномерного и показательного распределений. Решаем уравнение ![]() . Для этого, подставив выражение для плотности равномерного распределения на место
. Для этого, подставив выражение для плотности равномерного распределения на место ![]() , вначале вычислим интеграл в левой части уравнения:
, вначале вычислим интеграл в левой части уравнения:
![]() ,
,
а затем для вычисления значений uравномерно распределенной в интервале (a,b) случайной величины ![]() через значения gслучайной величины
через значения gслучайной величины ![]() , равномерно распределенной в интервале (0,1) просто выразим переменную uчерез переменную gиз уравнения
, равномерно распределенной в интервале (0,1) просто выразим переменную uчерез переменную gиз уравнения ![]() :
:
![]()
Заметим, что полученная формула очевидна. Действительно, для пересчета равномерно распределенной в интервале (0,1) случайной величины в случайную величину, равномерно распределенную в интервале (a,b), мы должны вначале «растянуть» диапазон значений единичной длины в диапазон значений (b-a) умножая значения gна (b-a), а затем переместить полученный результат из интервала (0,1) в интервал (a,b), прибавив к нему значение a.
Запись полученной формулы в виде функции языка С:
float uniform (float a, float b) {return rand()*(b-a)+a;}
позволит нам программно генерировать случайные величины с равномерным распределением в любом заданном конечном интервале значений (a,b).
Глава 2 Имитационное моделирование процесса
2.1 Постановка задач (Вариант №2)
Провести имитационное моделирование работы парикмахерской. Количество парикмахеров в парикмахерской – n. Время моделирования –t часов. Интервал времени между двумя последовательными посещениями парикмахерской клиентами моделировать случайной величиной τ1 с дискретным равномерным распределением в диапазоне значений (τ1min,…,τ1max) минут. Время обслуживания одного клиента моделировать случайной величиной τ2с распределением P(τ2). Цена обслуживания клиента определяется функцией времени обслуживания вида c=aτ2.
Если в момент прибытия очередного клиента парикмахеры заняты, то клиент помещается в очередь. Максимальная длина очереди 10 чел. Если длина очереди максимальна, то производится отказ в обслуживании очередного клиента.
Рассчитать:
§ количество обслуженных клиентов за период моделирования;
§ выручку парикмахерской R за период моделирования;
§ средний размер очереди;
§ число отказов r.
Параметры модели:
§ n=2;
§ t=8;
§ τ1min =1, τ1max =15;
§ P(τ2) = ( 10 12 13 14 15 16 17 18 19)
( 0,05 0,05 0,05 0,05 0,05 0,2 0,2 0,2 0,15)
(первая строка - значение случайной величины в минутах, вторая - соответствующие вероятности);
§ а=3
Определить методом машинного эксперимента параметр τ1max, максимизирующий выручку R при условии r=0. Средство реализации модели – программа на языке С++.
2.2 Общий алгоритм моделирования процесса
Алгоритм имитационного моделирования процессов данного типа структурируется вокруг следующих групп основных компонентов:
1. Организация цикла перебора отсчетов дискретного времени моделирования, т.е. собственно организация процесса как последовательности отдельных состояний системы в дискретном времени;
2. Наполнение этого цикла множеством независимых обработчиков случайных событий происходящих в моделируемой системе.
Таким образом, мы имеем общий способ построения алгоритмов подобного типа, который включает следующие основные компоненты:
1. Анализ событий в системе и проектирование структур данных необходимых для хранения информации связанный с этими событиями;
2. Разработка отдельных алгоритмов обработки этих событий включающих в общем случае модификацию параметров состояния системы и моделирование следующего события того типа, обработка которого производится этим алгоритмом;
Связывание отдельных разработанных выше алгоритмов и структур данных в единой программе.
2.3 Моделирование программы с заданными параметрами
В данной курсовой работе необходимо провести имитационное моделирование работы Парикмахерской. Для моделирования данной задачи мы используем СМО с N обрабатывающими устройствами без очереди с отказами. Алгоритм поставленной задачи, которая рассмотрена в п. 2.2. необходимо реализовать на языке программирования С++.
В качестве параметров модели используем следующие компоненты и макроопределения:
· Т - время моделирования (в мин.);
· RIN - генератор случайного потока поступающих в систему требований;
· RОN - генератор интервалов времени обработки требования обрабатывающим устройством;
· n– общее число мест в кафе.
Исходный текст программы начинается с определения параметров модели и прочих исходных данных. Все они определяются с помощью директивы препроцессора "#define". Макросы RIN и RОN определяют вызовы функций, моделирующих распределение интервалов времени между событиями прихода посетителей и интервалов времени от начала до завершения обслуживания посетителей, соответственно. А макрос Trafik определяет вызов функции, моделирующую средний трафик пользователей. Сами функции моделирования случайных последовательностей, распределенных по различным законам, определены в файле Rand.срр, текст которого подключается к тексту модели процесса с помощью директивы препроцессора "#include" в первой строке текста программной реализации модели. Константа "Т" определяет длительность периода моделирования в единицах дискретного времени моделирования (в минутах). Константа "n" задаёт число обрабатывающих посетителей. ton(i)=-1 определяет специальное значение для элемента массива ton( ), означающее, что место освободилось (компьютер свободен). Поскольку массив ton( ) предназначен для хранения моментов времени ухода посетителя, которые могут принимать лишь неотрицательные значения, то в качестве такого, сигнализирующего о незанятости компьютера значения, взято первое неиспользуемое отрицательное число - "-1".
Все переменные определяются как длинные целочисленные переменные. Это связано с тем, что диапазона значений простого типа int - от -32768 до 32767 может быть недостаточно для представления используемых значений данных модели. Далее следует собственно моделирующий алгоритм:
1 .Инициализация переменных:
1.1. Инициализация массива ton( ) – все парикмахеры помечаются как свободные присваиванием элементам массива значения "-1":
" for(i=0;i 2. Цикл перебора дискретных отсчётов времени периода моделирования: 2.1. Определение числа итераций цикла перебора дискретных отсчётов периода моделирования: "for(j=0;j 2.1.1 .Обработка ухода посетителя парикмахерской: 2. 1.1.1. Определение числа итераций цикла перебора устройств: "for(i=0;i падает с уходом посетителя ton(i): “if(ton(j)==i)”, и вход в тело цикла “{”, 2.1.1.1.1. освобождение места (парикмахера): “ ton(j)=-1;”; 2. 1.1. 2. 2. увеличение на единицу числа обслуживаемых посетителей: "nPos++"; 2. 1.1.3. Конец цикла 2.1.1.1.: "}". 2.1.2. Обработка прихода нового посетителя: 2. 1.2.1. Поиск первого свободного обрабатывающего устройства: "j=0; while(ton(j)!=-1) j++; 2. 1.2.2. Генерация момента прихода в парикмахерскую нового посетителя и сохранение его в переменной tin: “tin=ceil(RIN)+i;” 2.2. Конец блока цикла 2.1.: "}". 3. Завершение процесса моделирования: 3.1. Вывод результатов моделирования. 2.4 Разработка программной реализации алгоритма В данном разделе мы разрабатываем программную реализацию имитационного моделирования работы Парикмахерской. Помимо общих переменных, которые были описаны выше в п.2.3., в этом разделе можно описать и частные переменные, которые используются в программе, разработанной на языке программирования С++: В программной реализации используются следующие частные переменные: · i, j- используются для хранения вспомогательных индексных значений; · t - дискретные отсчёты времени периода моделирования; · tin – входящий поток, время прихода посетителя (момент поступления в систему следующего требования); · ton ( ) - моменты завершения обработки требований соответствующими элементам массива обрабатывающими устройствами, то есть массив для сохранения интервалов времени ухода посетителей; · Cena–цена обслуживания клиента; · r– число отказов пользователям; · m– число обслуженных посетителей; R-выручка парикмахерской за период моделирования Программная реализация алгоритма производится в несколько этапов: 1. Подключение в программу заголовочных файлов: #include //включение в программу текстов заранее подготовленных файлов #include<iostream.h> //содержит потоки данных ввода/вывода #include<math.h> //хранятся математически функции #include #include # include #define //определение параметров модели и прочих исходных данных на глобальном уровне, описанной в п. #define RCLIENTS x1(discrete(p1)) float x1()={7,8,9,10,11,12,13,14,15}; float p1()={0.05, 0.05, 0.05, 0.2, 0.2, 0.2, 0.05, 0.05, 0.15}; #define CENA x2(discrete(p2)) floatx1()={10,12,13,14,15,16,17,18,19}; floatp1()={0.05, 0.05, 0.05, 0.05, 0.05, 0.2, 0.2, 0.2, 0.15}; #defineC (125*125*125*125*5) //объявление мультипликативного конгруэнтного метода, которое описывается в п.1.3. #definen 2// общее число парикмахеров #defineT (8*60*30) // период моделирования (в мин.) 2. Генерация мультипликативным конгруэнтным методом псевдослучайной последовательности чисел: floatrand(void) //генерация псевдослучайной последовательности с равномерным распределением { static unsigned long int u=C; // static – модификатор для того, чтобы локальная переменная u сохраняла значение между двумя последующими обращениями к этой функции u=u*C; //С - константа returnu/float(0xfffffffful); // (0xfffffffful) – максимально беззнаковые целое число, заданное в шестнадцатеричной форме. } 3. Вызов функций моделирования: //функция моделирования показательного распределения, описанная в п.1.7. unsigned int discrete( float p( )) { float s, r; int k=0; s=p( ); r=rand( ); while (s { k++; s+=s+p(k); } returnk; } 4. Инициализация unsigned long int i,j,cost, R,r,n,k; float t, tin; m=0; k=0; R=0; 5. Запускпрограммы tin=RIN; for(i=0;i 6. Обработказавершения for(j=0;j { m++; ton(j)=-1; } 7. Обработка очередного входящего события if(i==tin) { j=0; while((ton(j)!=-1) && (j if(j!=N) { i=RCLIENTS; n++; for(;t if(rand1()<=P) { cost=cost+a*CENA; k++; } } else r++; tin=RIN+i; } } 8. Выводимыерезультаты: cout<<"........................ Rezultati modelirovaniya .............................."; cout<<"1.Posetili parikmakherskuy:"< cout<<"2.Iz nikh obclujeno : "< cout<<"3. Iz nikh ne obclujeno: "< cout<<"5Viruchka sostavila: "< getch(); } 2.5 Моделирование программы с заданными параметрами Запустив программу, написанную на языке С++, мы получили следующие результаты согласно исходным данным: Рис3. Результат выполнения разработанной программы При данном количестве парикмахеров– 2, было рассчитано: · Общее количество посетителей-25 человек; · Общее количество обслуженных клиентов-20человек; · Oбщее количество отказов-5 человек; · Полученная прибыль составила 13690руб. 2.6 Машинный эксперимент с разработанной моделью В результате машинного эксперимента с разработанной моделью мы получили следующие данные, приведенные в таблице 1: Таблица 1. Полученные результаты задачи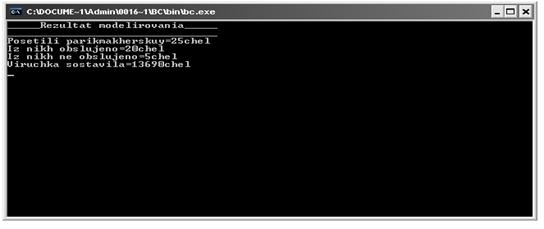
Количество парикмахеров Общее кол-во посетителей Число обслуженных Число отказов Выручка 1 17 13 4 8398 2 25 20 5 13690 3 45 27 18 17530 4 57 33 24 16890 5 64 43 21 26540 6 78 51 27 23540 7 89 63 26 26540 8 110 76 34 31790 9 124 81 43 37950 10 140 97 43 39890